
Assertivní sobi
Březnová slezina se povedla — dorazilo sedmnáct lidí, nad talky se rozjela vřelá debata a projektor se nám v průběhu přednášek vypnul jen čty-ři-krát!
Nebojte se testování
V prvním bloku vystoupil Honza Bednařík se svou přednáškou o testování. Honza je aktivní Python programátor, a ikdyž promítané slajdy primárně obsahovaly ukázky z tohoto programovacího jazyka, komentoval je i obecnějšími radami, které se dají aplikovat na jiné prostředí.
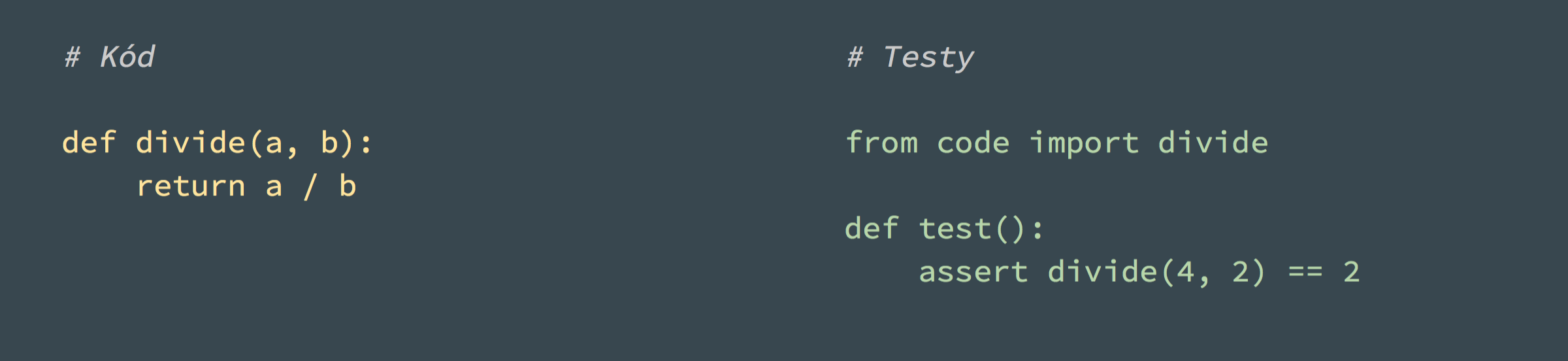
To jak pohodlně se vám budou testy psát záleží i na volbě testovacího frameworku. Na ukázce výše je jednoduchá funkce a její test ve frameworku pytest. Otestovat stejný kód s variantou knihovny xUnit je pracnější:
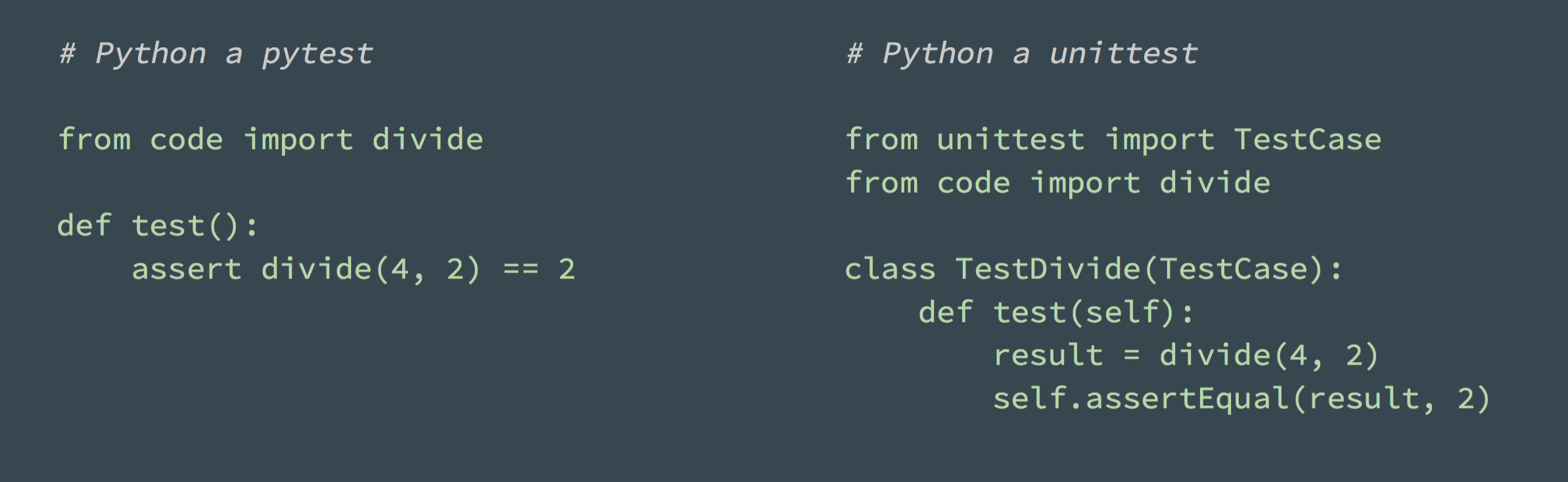
Pro psaní testů existuje celá řada doporučení a filozofií, ze kterých Honza vyzdvihl hlavně tyto:
- Jeden test by měl prověřovat jedinou situaci. Psát tučné testovací funkce, které kontrolují více situací je antipattern. Pokud něco selže tak se sice můžete dozvědět na jakém řádku v testu nastal problém, ale už nezjistíte, jestli je potíž i v kódu který jej následuje.
- Název testu by neměl doslovně popisovat co se děje uvnitř (to by mělo oko programátora poznat samo). Lepší je volit takové pojmenování, které vystihuje testovanou situaci.
- TDD, tedy Test Driven Development, je způsob vývoje, při kterém se nejdříve píšou testy a teprve poté samotný aplikační kód. Tímto postupem přirozeně vzniká dobře protestovaný kód a programátor mívá menší pokušení psát zbytečnosti. I v TDD ale hrozí scestí ve formě kódu, který sice formálně testy prochází, ale jeho implementace reaguje správně pouze na testované scénáře. Chod v reálných podmínkách nemusí dopadnout dobře.
- Při testech se někdy nevyhneme mockování, tj. nahrazování reálných objektů naší vlastní (zjednodušenou) implementací. Pokud má test odhalit problémy v práci s časem, externími API službami či s mezními situacemi, určitě se poohlédněte po mock, stub či fake knihovnách.
- Testy které musí prověřovat chování s databází bývají obvykle pomalé. Pokud to jde, vyhněte se jim (otestuje objekt či funkcionalitu bez ní). Pokud to nejde, narvěte ji na SSD disk či do RAM. Plnění databází řešte generátory či factory funkcemi, před fixturami zdrhněte (rozuměj, špatně se udržují).
Celou Honzovu přednášku si můžete poslechnout na YouTube:
Promítané slajdy najdete na našem tkalcovském webu.
Na konci prvního bloku si vzal slovo i Zdeněk Rejda a prolítnul s náma testovaní v jazyce C. No peklo, co vám máme povídat:
ELK, Logování s ❤
V druhém bloku vystoupil Michal Valoušek s přednáškou o ELK stacku — třech klíčových opensource technologiích, které dohromady tvoří šikovný nástroj pro sběr, analýzu a vizualizaci vašich logů.
Pod písmenem E se schovává Elasticsearch, vyhledávací a analytický
engine.
L představuje Logstash, vycucávače a zpracovávače logů. Je to právě
Logstash, do kterého budete logy odesílat, anebo jeho prostřednictvím vybírat z
nejrůznějších míst. Co Logstash zkonzumuje a zprocesuje, uloží do
Elasticsearche.
Posledním dílkem skládanky je K jako Kibana, což je javascriptová
aplikace napsaná v Angularu, která vám v pěkném UI zpřístupní data uložená v
Elasticsearchi a umožní nad nimi provádět sofistikované dotazy a
vizualizace.
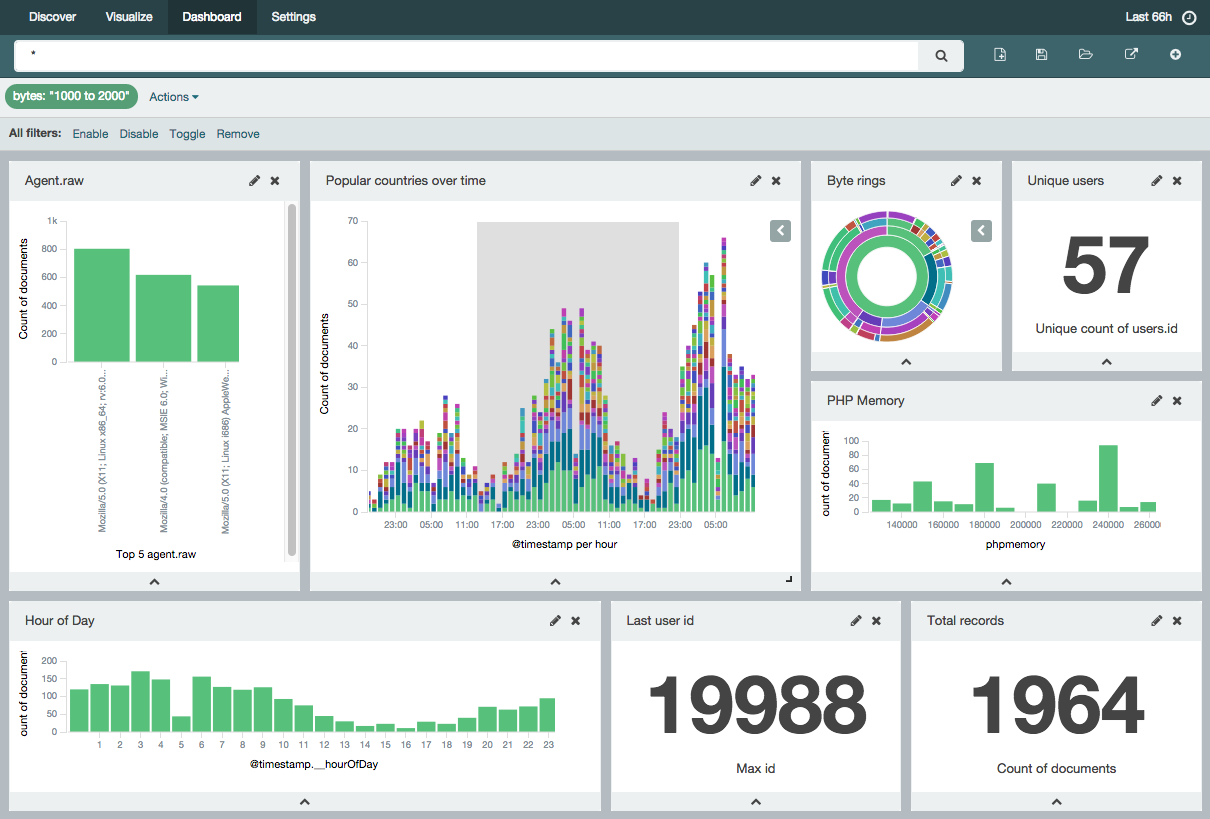
Přednáška byla pojata prakticky. Po úvodním seznámení s technologiemi jsme nahodili ve VirtualBoxu Ubuntu mašinu, sestavili v ní Ansible skriptem celý stack a začali si s losem hrát naživo.
Nejprve jsme měli Logstash nakonfigurován tak, aby konzumoval pouze
hlášky přicházející ze syslogu. Aby nám ale Kibana začala vůbec něco kloudného
zobrazovat, museli jsme se přihlásit na virtuální stroj a dráždit ji příkazy
typu "logger maslo" či "logger chleba".
To jsme vzápětí vyřešili sledováním logů ze samotné Kibany, takže se nám v
UI prostředí začal objevovat bohatší set dat, nad kterými už bylo možné
provádět rozumnnější filtrování a dotazy.
Pořád jsme ale jen škrábali po povrchu. Teprve po nastavení sekce filter v
konfiguraci Logstashe, parsování vstupních logů a simulovaném trafficu nad
statický webem všem došlo, jak silný nástroj ELK je. V jediném prostředí
může operátor provádět dotazy napříč celým systémem a vytvářet z nich smysluplné
vizualizace. Čím více dat se vám povede do ELKu nasypat, tím větší užitek z něj
budete mít.
Celý výstup jsme nahrávali a vystavili na Youtube:
Slajdy jsou k nahlédnutí zde. Pokud si budete chtít ELK stack osahat u
sebe, podívejte se na tento GitHub repozitář. V adresáři demo/ je
popsán kompletní postup instalace.
Díky všem co jste přišli a vystupujícím dvojnásob.
Obrázek Kibany via https://www.elastic.co/assets/blt45376e159402a169/Screen-Shot-2014-12-15-at-12.28.30-PM.png
{kind=link}